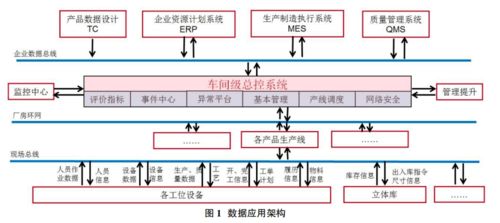
微服务数据依赖难题的破解之道 以数据处理服务为核心
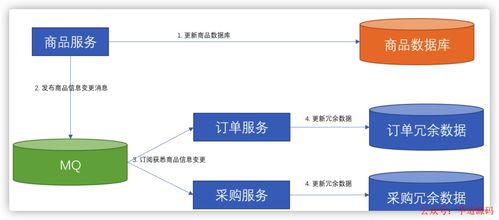
在微服务架构中,服务间的数据依赖是普遍存在的挑战,尤其是在数据处理服务与其他业务服务之间。一个服务可能需要另一个服务的数据来完成自己的业务逻辑,但直接的数据共享或数据库耦合会破坏微服务的自治性和松耦合原则。妥善处理这些依赖,是保障系统弹性、可维护性和可扩展性的关键。
核心原则:避免直接数据库耦合
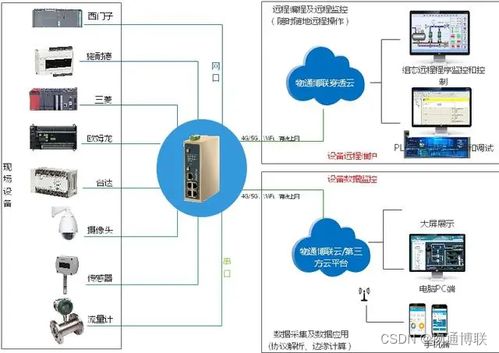
首要原则是,一个微服务不应直接访问另一个微服务的私有数据库。这会导致服务间的实现细节紧密绑定,一旦数据模型变更,影响会蔓延至多个服务,使得独立部署和扩展变得困难。数据处理服务尤其需要遵守此原则,因为它通常是数据的生产者和消费者。
主流处理模式
- API调用(同步)
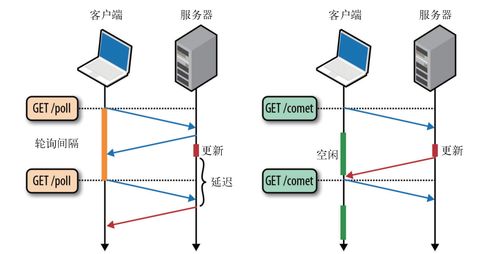
- 方式:服务A通过服务B提供的定义良好的RESTful API或gRPC接口,实时请求所需数据。
- 适用场景:对数据实时性要求高,且调用链路短、成功率有保障的场景。数据处理服务可作为客户端调用其他服务获取原始数据,或作为服务端提供处理后的数据。
- 挑战:增加了网络延迟和故障点。需通过熔断、降级、超时机制保障稳定性。可能造成循环依赖。
- 异步事件驱动
- 方式:服务在自身数据变更时,向消息中间件(如Kafka, RabbitMQ)发布一个领域事件。其他感兴趣的服务(如数据处理服务)订阅这些事件,异步地更新自己的数据副本或触发处理流程。
- 适用场景:数据最终一致性即可,需要解耦、提升系统吞吐量和响应能力的场景。数据处理服务天然是事件的消费者,可进行实时流处理或批量分析。
- 优势:彻底解耦,服务间仅通过事件契约联系,提高了自治性和弹性。
- 数据副本与物化视图
- 方式:通过事件驱动或CDC(变更数据捕获)工具,将其他服务关心的数据以合适的模型复制到本地。数据处理服务可以维护一个为查询优化的数据副本,避免频繁的跨服务调用。
- 适用场景:读多写少,且查询模式与其他服务数据模型不同的场景。数据处理服务可以构建聚合、分析型的物化视图。
- 注意:需接受数据的短暂延迟,并明确数据所有权和更新机制。
数据处理服务的特殊策略
作为专门处理数据的服务,它可以采用更主动和聚合的策略:
- 充当数据聚合层:通过调用多个服务的API或消费多个事件流,将分散的数据按业务需求聚合、关联,形成新的数据产品,并通过API提供给其他服务消费。这避免了其他服务自行处理复杂的数据依赖。
- 提供统一查询接口:对于复杂的跨域查询,可以由数据处理服务封装底层对多个微服务的调用或查询本地数据副本,对外提供一个粗粒度的、业务友好的查询接口。
- 维护权威数据索引:对于需要跨服务关联查询的场景,数据处理服务可以维护一个核心业务ID的索引,记录其在不同系统中的存在性和关键元数据,但不包含详细业务数据,从而指引查询路由。
实践建议
- 明确边界与所有权:严格定义每个服务的领域边界和数据所有权。数据处理服务应聚焦于“加工”,而非“拥有”核心业务数据。
- 契约先行:服务间通过明确定义的API契约或事件契约进行通信,并保持向后兼容。
- 拥抱最终一致性:在分布式系统中,强一致性成本高昂。大多数业务场景可接受秒级或分钟级的最终一致性,这为异步化提供了空间。
- 监控与可观测性:必须全面监控服务间调用的延迟、错误率,以及事件管道的积压情况,以便快速定位数据同步问题。
###
处理微服务间的数据依赖,本质是在自治与协作间寻找平衡。对于数据处理服务,其角色更应是数据的协调者与价值提升者,而非简单的通道。通过结合同步API满足实时性要求,利用异步事件驱动实现解耦与扩展,并适时使用数据副本来优化查询,可以构建出既清晰又健壮的微服务数据交互体系。关键在于根据具体的业务场景、一致性要求和性能需求,灵活选择和组合这些模式。
如若转载,请注明出处:http://www.pdhqd.com/product/4.html
更新时间:2026-04-04 14:06:36